Wav2Vec2.0 paper notes
Posted on Sat 20 May 2023 in paper review Updated: Sat 20 May 2023 • 3 min read
Wav2vec2.0, as the name already suggests, claims to receive a raw audio file in its waveform and convert it to a vector (encode it in the latent space). Therefore, many downstream tasks can be performed on top of this vector representation extracted by the model. Meta claims that using a cross-lingual training method produces more useful representations for low-resource languages since they can benefit from other related languages.
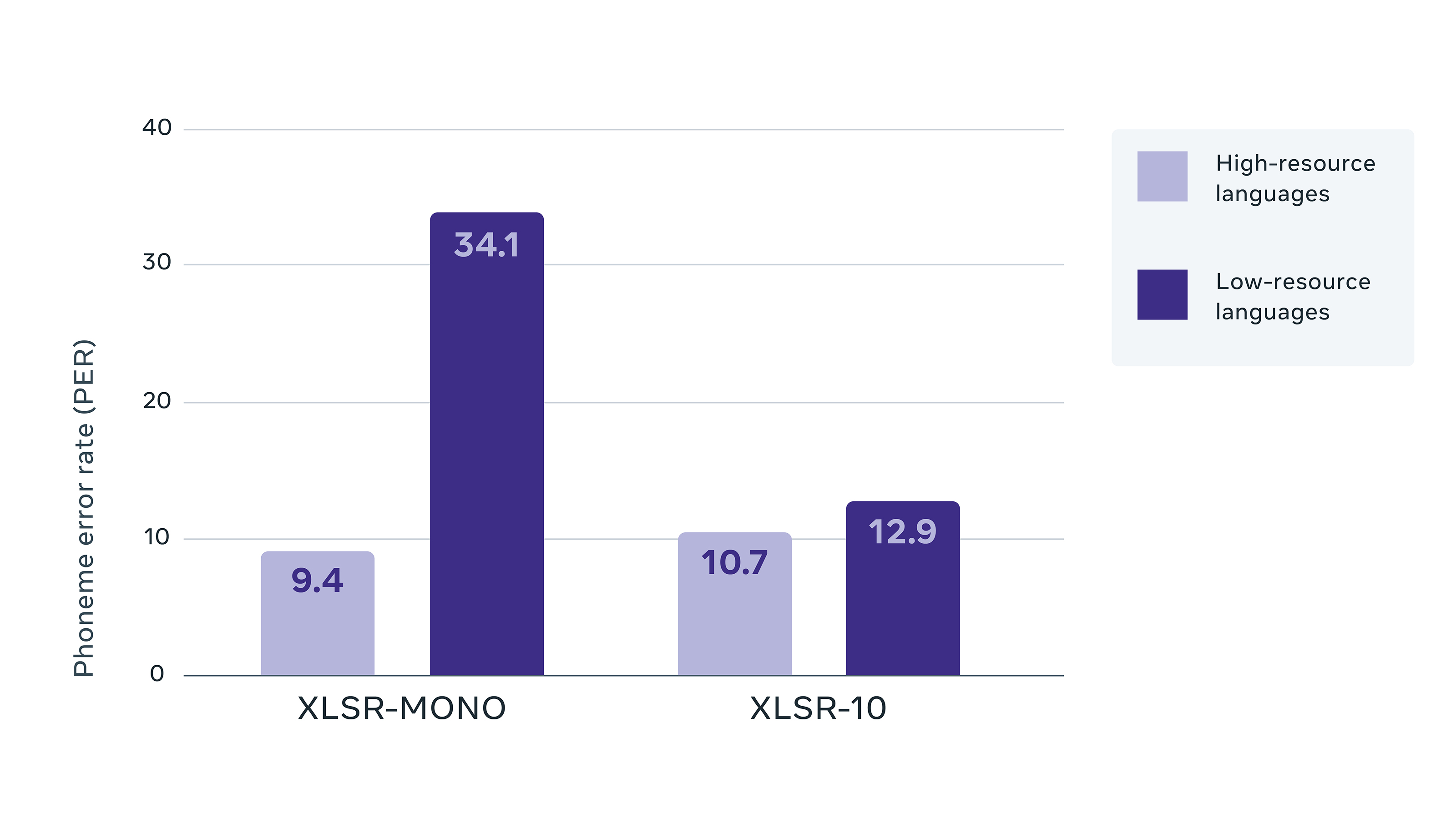
Results on the Common Voice benchmark in terms of phoneme error rate (PER), comparing training on each language individually (XLSR-Mono) with training on all ten languages simultaneously (XLSR-10).
It's trained on a self-supervised learning approach. It has achieved SOTA on Librispeech 100h subset on the Automatic Speech Recognition task using 100x fewer data.
The model consists of a few blocks. When we input our waveform, it passes through a feature encoder. After extracting the initial features from an audio snippet, we compute a discrete representation of it (I will cover that in more detail later on). Then we pass the initial features as it is to a transformer architecture, and the training objective is to make the model distinguish between the output of the transformers given the initial components and the quantized versions of other "chunk" audio snippets. We are trying to make the model learn a good representation for our audio snippet.
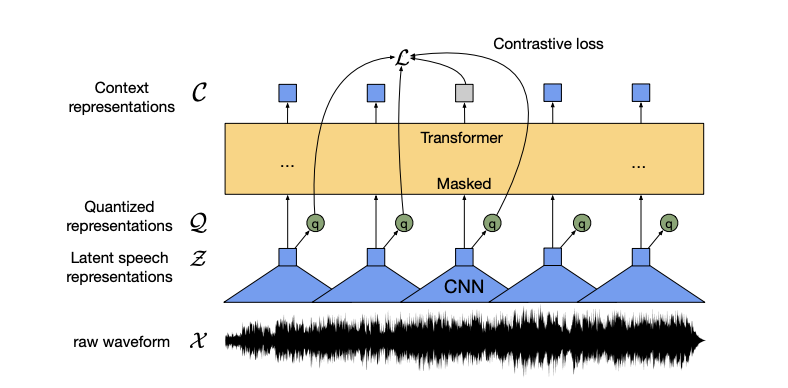
Feature encoder
This block consists of multi-layer temporal convolutional neural networks (CNN) followed by layer normalization and applied to the GELU activation function. The raw waveform is normalized to zero mean and unit variance (previous studies have shown that this preprocessing step benefits the model's learning). Given the waveform X, we compute the latent representations Z of it - more specifically, we compute latent representations for each 25ms chunk.
Contextualized representation with transformers
Now that we have the latent representations, we want to pass them through our transformers model to obtain more accurate context representations C. It's worth mentioning that we do not use any positional encoding to preserve "temporal" information to the input due to the use of temporal convolutions in our feature encoder block, which works similarly. They also add a GeLu activation function and a layer normalization layer to the output of the convolutions.
Quantization module
The quantization module aims to discretize the feature-encoder representations to a finite set of speech representations. So that given an input feature vector in Z, we compute its Q version. The authors created G codebooks and each consisting of V code words. So given our latent representation vector z1, we will choose from each codebook the best code words that represent our current vector. After that, we concatenate all code words to produce our q1 quantized vector.
What are the differences from the previous w2v?
The main difference is the introduction of the transformer architecture in the latter method. The first word2vec was also pre-trained in an SSL manner but using a different learning objective. In fact, it optimizes the model so that it should be able to identify future samples from a given audio signal. Regarding the architectural changes, the first version proposed used another multi-layer convolutional neural network as the "context network."
The pretraining and finetuning are widely available on the Meta AI research GitHub repository and can be used with very few commands. As for future steps, they say that their engineering team is working on adapting the code base to run on cloud TPU infrastructure.
References
Wav2vec 1.0 paper
Wav2vec 2.0 paper
Meta AI blog post
github page