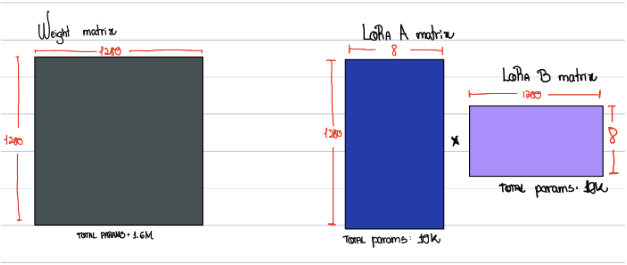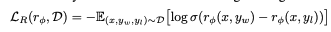
Aligning models to human values and desires is a formidable task, particularly when we're working with vast datasets that resist meticulous control. Concerns arise when language models spew out content that could be false or harmful. Luckily, advancements in AI research are opening pathways for safer and more reliable interactions …
Enhancing AI Alignment with Direct Preference Optimization
Posted on Wed 14 February 2024 in deep learning • 3 min read